Normalize your data distribution with imperio BoxCoxTransformer
Feature engineering is the process of transforming your input data in such a way that it will be more representative of the Machine Learning Algorithms. However, it is very often forgotten because of the inexistence of an easy-to-use package. That’s why we decided to create the one — imperio, the third our unforgivable curse.
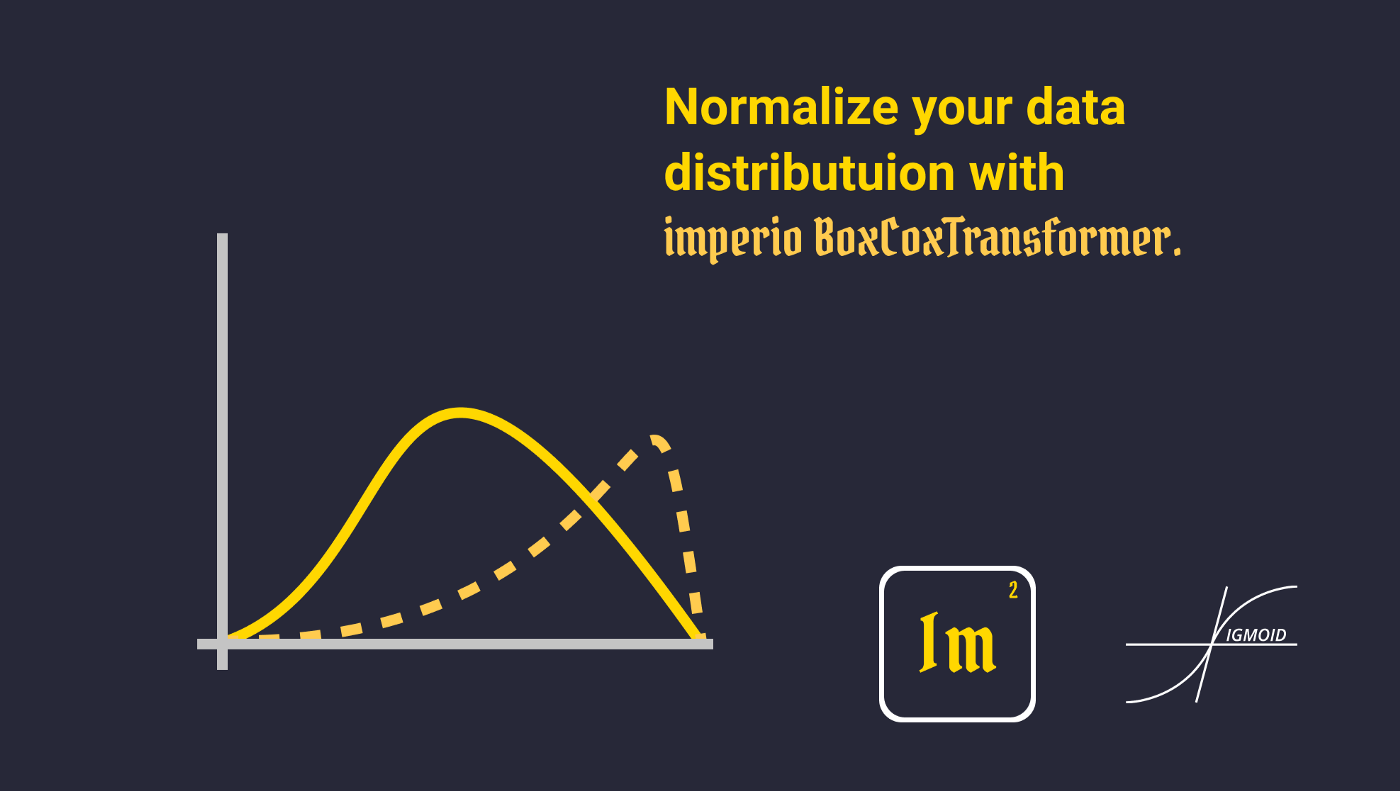
One of the biggest problems with data in Data Science is its distribution, it almost every single time isn’t normal. It happens because we cannot have all samples in the world in one data set. However, there exists a bunch of methods that can change that. Today we will take a look at the Box-Cox.
How Box-Cox transformation works?
Box-Cox transformation is a transformation of a non-normal variable into a normal one. The normality of the data is a very important assumption in statistics. From the point of view of statistics, it allows you to run more statistics tests on the data, while from the Machine Learning point of view it allows algorithms easier to learn.
Box-Cox applies the following formula to the data:

This formula gives the following effect:

Using imperio BoxCoxTransformer:
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t installed the library, then you can do it by typing the following comand:
pip install imperio
Now you can import the transformer, fit it and transform some data.
from imperio import BoxCoxTransformer
boxcox = BoxCoxTransformer()
boxcox.fit(X_train, y_train)
X_transformed = boxcox.transform(X_test)
Also, you can fit and transform the data at the same time.
X_transformed = boxcox.fit_transform(X_train, y_train)
As we said it can be easily used in a sci-kit learn pipeline.
from sklearn.pipeline import Pipeline
from imperio import BoxCoxTransformer
from sklearn.linear_model import LogisticRegressionpipe = Pipeline(
[
('boxcox', BoxCoxTransformer()),
('model', LogisticRegression())
])
Besides the sci-kit learn API, Imperio transformers have an additional function that allows the transformed to be applied on a pandas data frame.
new_df = boxcox.apply(df, target = 'target', columns=['col1'])
The BoxCoxTranformer constructor has the following arguments:
- l (float, default = 0.5): The lambda parameter used by Box-Cox Algorithm to choose the transformation applied to the data.
- index (list, default = None): The list of indexes of the columns to apply the transformer on. If set to None it will be applied to all columns.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- columns (list, default = None): The list with the names of columns on which the transformers should be applied.
Now let’s apply it to a data set. We will use it on the Pima diabetes data set. We will apply it to all columns, however, we recommend applying it only on the numerical columns. Bellow, you can see the Logistics Regression performance before applying the Box-Cox transformer and after applying it.

As we can see the accuracy of the Logistic Regression model raised from 0.72 to 0.77 after applying a distribution normalizer to our data.

Made with ❤ from Sigmoid.