Reduce the outliers influence with imperio SpatialSignTransformer


Outliers are a big problem of almost all types of Machine Learning algorithms. Would be fine if somehow with a data preprocessing technique would be possible to eliminate or at least to reduce their influence on data. You can consider yourself lucky because it exists — Spatial Sign is its name.
How does Spatial Sign work?
By applying an l2 normalization on the data, this technique if the data is normalized then it brings all points in a circle doesn’t matter if it’s an outlier or not, like the plot below. Even if the data isn’t normalized, it will bring all samples closer to each other. The formula for this technique is the following one.


Using imperio SpatialSignTransformer.
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t install the library, then you can do it by typing the following command:
pip install imperio
Now you can import the transformer, fit it and transform some data.
from imperio import SpatialSignTransformer
spatial_sign = SpatialSignTransformer()
spatial_sign.fit(X_train, y_train)
X_transformed = spatial_sign.transform(X_test)
Also, you can fit and transform the data at the same time.
X_transformed = spatial_sign.fit_transform(X_train, y_train)
As we said it can be easily used in a sci-kit learn pipeline.
from sklearn.pipeline import Pipeline
from imperio import SpatialSignTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScalerpipe = Pipeline(
[
('scaler', StandardScaler()),
('spatial_sign', SpatialSignTransformer()),
('model', LogisticRegression())
])
Besides the sci-kit learn API, Imperio transformers have an additional function that allows the transformed to be applied on a pandas data frame.
new_df = spatial_sign.apply(df, target='target', columns=['col1'])
The SpatialSignTransformer constructor has the following arguments:
- index (list, default = None): The list of indexes of the columns to apply the transformer on. If set to None it will be applied to all columns.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- columns (list, default = None): The list with the names of columns on which the transformers should be applied.
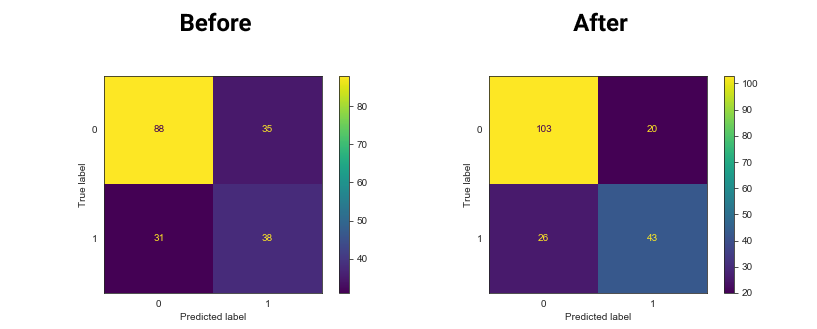
Now let’s apply it to a data set. We will use it on the Pima diabetes data set. We will apply it to all columns, however, we recommend applying it only on the numerical columns. Bellow, you can see the K-Nearest Neighbors performance before applying the Standard Scaler and Spatial Sign and after applying it. We increased the accuracy by 11%.

Made with ❤ by Sigmoid.