Retain Target Information with imperio TargetImputationTransformer

As we said in the article about FrequencyImputationTransoferm,
usually, categorical values are replaced by integer numbers. However, this approach is very dangerous for linear models, because of the false correlation that may appear. A step forward from this technique is One Hot Encoding (or Dummy variables). But even Dummy variables have their drawbacks — the matrix is becoming very large, and even worse it became sparse. We also said that Frequency imputation has a big drawback, if there are two or more categories with the same frequency then this category will collide in this representation. This problem is solved by Target Imputation, let’s see how.
How does Target Imputation work?
The idea behind Target Imputation is pretty simple too. In case of a regression problem, we are replacing the category with the mean of the target column for this category, as shown below. In the case of classification problems, we replace categories with the frequency of the most common class for this category.

This method assumes that in such a way the new representation will present more information about the target column.
Using imperio TargetImputationTransformer:
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t install the library, then you can do it by typing the following command:
pip install imperio
Now you can import the transformer, fit it and transform some data. Don’t forget to indicate the indexes of the categorical values!
from imperio import TargetImputationTransformer
target = TargetImputationTransformer(index = [2, 6, 8, 10, 11, 12])
target.fit(X_train, y_train)
X_transformed = target.transform(X_test)
Also, you can fit and transform the data at the same time.
X_transformed = target.fit_transform(X_train, y_train)
As we said it can be easily used in a sci-kit learn pipeline.
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegressionpipe = Pipeline(
[
('target', TargetImputationFrequency(index = [10, 11, 12]),
('model', LogisticRegression())
]
)
Besides the sci-kit learn API, Imperio transformers have an additional function that allows the transformed to be applied on a pandas data frame.
new_df = target.apply(df, target = 'target', columns = ['col1'])
The TargetImputationTransformer constructor has the following arguments:
- reg (bool, default = True): A parameter that indicates wherever it is a classification or regression task.
- index (list, default = ‘auto’): The list of indexes of the columns to apply the transformer on. If set to ‘auto’ it will find the categorical columns by itself.
- min_int_freq (int, default = 5): The minimal number of categories that a column must have to be transformed. Used only when the index is set to ‘auto’.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- columns (list, default = None): The list with the names of columns on which the transformers should be applied.
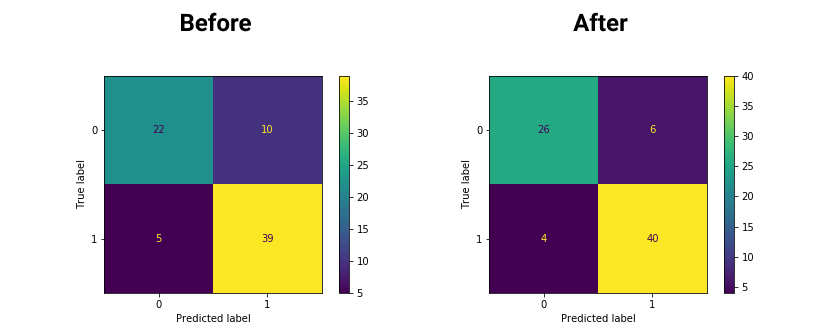
Now let’s apply it to the Heard Disease UCI data set. However we will apply it only on the non-binary columns: ‘cp’, ‘restecg’, ‘exang’, ‘slope’, ‘ca’, and ‘thal’. Below are illustrated the confusion matrices before and after applying the transformation. We got 6% more accuracy.

Made with ❤ by Sigmoid!