Transform your categorical columns with imperio SmoothingTransformer


Feature engineering is the process of transforming your input data in such a way that it will be more representative of the Machine Learning Algorithms. However, it is very often forgotten because of the inexistence of an easy-to-use package. That’s why we decided to create the one — imperio, the third our unforgivable curse.
One of the main problems that appear when working with data is the categorical values. There are a lot of techniques that help to transform categorical data into numeric but every one of them is working differently and you never know which will work better for your data. In this article, we will present you with the Smoothing technique.
How SmoothingTransformer works?
Smoothing is a regularization technique that is based on the following idea. Usually, a categorical column is encoded with the Target Imputation technique, but it doesn’t care if the category is big or small, it applies the same operation to every category which is not very correct. In Smoothing, if the category is big, and has a lot of data points, then we can trust the estimated encoding, but if the category is rare it’s the opposite. The formula down below uses this idea. It has hyper parameter alpha that controls the amount of regularization. When alpha is zero, we have no regularization, and when alpha approaches infinity everything turns into a global mean.
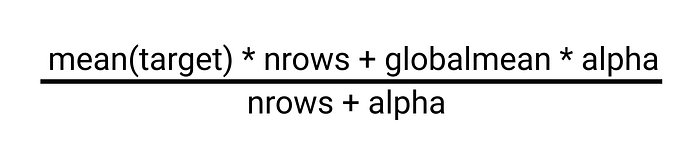
In some sense, alpha is equal to the category size we can trust. It’s also possible to use some other formula, basically anything that punishes encoding software categories can be considered smoothing. Smoothing obviously won’t work on its own but we can combine it with, for example, CV loop regularization.
Using imperio SmoothingTransformer:
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t install the library, then you can do it by typing the following command:
Now you can import the algorithm, fit it and transform some data.
smoothing = SmoothingTransformer()
X_transformed = smoothing.fit_transform(X,y)
As we said it can be easily used in a sci-kit learn pipeline.
from imperio import SmoothingTransformer
from sklearn.linear_model import LogisticRegression
pipe = Pipeline(
[
('smooth', SmoothingTransformer()),
('model', LogisticRegression())
])
Besides the sci-kit learn API, Imperio transformers have an additional function that allows the transformer to be applied on a pandas data frame.
The SmoothingTransformer constructor has the following arguments:
- alpha(float, default = 100): Number that controls the amount of regularization.
- categorical_index (list, default = None): The list of indexes of the categorical columns to apply the transformer on. If set to None it will be applied to all columns.
- min_int_freq (int, default = 10): Number that indicates the number of minimal values in a categorical column for the transformer to be applied.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- columns (list, default = None): The list with the names of columns on which the transformers should be applied.
Now let’s test with Heart Disease, a classic Machine Learning dataset. Here we set index=[2,6,10,11,12] in the algorithm constructor to show what are the categorical columns.

As we can observe from confusion matrices, initially we got 77% accuracy, and after applying SmoothingTransformer we obtained 83% accuracy.

Thank you for reading!
Follow Sigmoid on Facebook, Instagram, and LinkedIn:
https://www.facebook.com/sigmoidAI
https://www.instagram.com/sigmo.ai/
https://www.linkedin.com/company/sigmoid/