Use Entropy to find the where NaN if informative with Kydavra ShannonSelector

NaN values are one of the biggest problems in Machine Learning. However, problems are coming not from its presence, but from not knowing what they are meaning. Sometimes it is a full join that generates NaN values, in other cases, it means an imperfection of a sensor, in other cases, only the god knows what this NaN value means.
That’s why we at Sigmoid decided to add to kydavra a method that will decide which columns with NaN values are informative and what not.
Using ShannonSelector from Kydavra library.
If you still haven’t installed Kydavra just type the following in the command line.
pip install kydavra
If you already have installed the first version of kydavra, please upgrade it by running the following command.
pip install --upgrade kydavra
Next, we need to import the model, create the selector, and apply it to our data:
from kydavra ShannonSelector
shannon = ShannonSelector()
selected_cols = shannon.select(df, 'target')
The select function takes as parameters the panda’s data frame and the name of the target column. The ShannonSelector takes the following parameters:
- select_strategy (str, default = ‘mean’) the strategy used to choose the columns with informative NaN values. The allowed values are ‘mean’ and ‘median’. If the Information gain calculated by the selector is smaller that the given statistics, it is thrown away.
- nan_acceptance_level (float, default = 0.5) the minimal quantity of NaN values in a column to be accepted as informative.
Let’s see an example:
As an example of the uses of ShannonSelector I will show its performance on the Yelp Data Set. After converting the yelp_academic_dataset_business.json file into a data frame we got the following columns:
Index(['business_id', 'name', 'address', 'city', 'state', 'postal_code',
'latitude', 'longitude', 'stars', 'review_count', 'is_open',
'categories', 'BusinessAcceptsCreditCards', 'BikeParking',
'GoodForKids', 'ByAppointmentOnly', 'RestaurantsPriceRange2', 'Monday',
'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday',
'garage', 'street', 'validated', 'lot', 'valet', 'hours', 'attributes',
'DogsAllowed', 'WiFi', 'RestaurantsAttire', 'RestaurantsTakeOut',
'NoiseLevel', 'RestaurantsReservations', 'RestaurantsGoodForGroups',
'HasTV', 'Alcohol', 'RestaurantsDelivery', 'OutdoorSeating', 'Caters',
'WheelchairAccessible', 'AcceptsInsurance', 'RestaurantsTableService',
'Ambience', 'GoodForMeal', 'HappyHour', 'BusinessAcceptsBitcoin',
'BYOB', 'Corkage', 'GoodForDancing', 'CoatCheck', 'BestNights', 'Music',
'Smoking', 'DietaryRestrictions', 'DriveThru', 'HairSpecializesIn',
'BYOBCorkage', 'AgesAllowed', 'RestaurantsCounterService',
'Open24Hours'],
dtype='object')
64 columns in total. The task was to predict if a business is open or not by the ‘is_open’ column. However many businesses don’t have a lot of parameters defined in their dictionaries, so the data frames have a lot of columns with many NaN values. That’s why we will apply the ShannonSelector on it.
Note that we erased some columns manually, the columns that are names, ids, and others. That’s the full list of manually erased columns:
['business_id', 'name', 'address', 'postal_code', 'street', 'state', 'categories']
That’s how we applied the ShannonSelector.
from kydavra import ShannonSelectorshannon = ShannonSelector(nan_acceptance_level=0.1)selected_cols = shannon.select(df, 'is_open')
It selected 32 columns (of course the target column remained). These are the remained columns:
Index(['city', 'latitude', 'longitude', 'stars', 'review_count',
'BusinessAcceptsCreditCards', 'BikeParking', 'Saturday', 'Sunday',
'DogsAllowed', 'WiFi', 'Caters', 'WheelchairAccessible',
'AcceptsInsurance', 'RestaurantsTableService', 'GoodForMeal',
'HappyHour', 'BusinessAcceptsBitcoin', 'BYOB', 'Corkage',
'GoodForDancing', 'CoatCheck', 'BestNights', 'Music', 'Smoking',
'DietaryRestrictions', 'DriveThru', 'HairSpecializesIn', 'BYOBCorkage',
'AgesAllowed', 'RestaurantsCounterService', 'Open24Hours', 'is_open'],
dtype='object')
A quite good result and the main value is that it wasn’t performed manually.
How does it work?
ShannonSelector got his name in name of the Claude Shannon — the father of information theory. It uses the information theory to decide by replacing the NaN values with a certain value can help you to classify the target classes. If not then the column is thrown away. If you want some more mathematical background, look at the graphic below.

As you can see, in the example above for the Class1 we have a lot of NaN value almost all of them, while in Class2 almost all values are present, so replacing all NaN values in this case with a specific value, like ‘None’ can add a powerfull feature to our model.
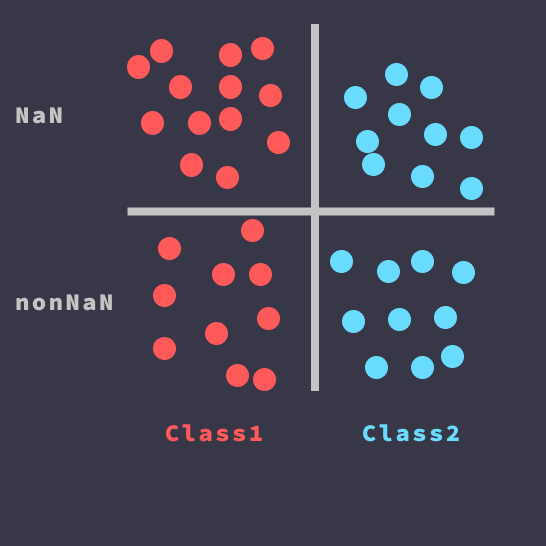
In the second case, the situation is worse. Because the NaN values are relatively uniformly distributed between classes, we wouldn’t add much information if we will replace the NaN value with a specific value, so it will be thrown away.
All this intuition is done mathematically by entropy and information gain, like in decision trees. If you want to find more, please consult the bibliography.

With ❤ by Sigmoid.
Biography:
- https://en.wikipedia.org/wiki/Information_theory
- https://en.wikipedia.org/wiki/Entropy
- https://en.wikipedia.org/wiki/Information_gain_in_decision_trees