Whiten your data with imperio ZCATransformer


Feature engineering is the process of transforming your input data in such a way that it will be more representative of the Machine Learning Algorithms. However, it is very often forgotten because of the inexistence of an easy-to-use package. That’s why we decided to create the one — imperio, the third our unforgivable curse.
How ZCATransformer works?
Whitening or Sphering is a data pre-processing step. It can be used to remove correlation or dependencies between features in a dataset. This may help to better train a machine learning model.
Eigenvalues and eigenvectors are first calculated from the covariance of a zero-centered data set. These are then used for Whitening the data using ZCA (zero component analysis method).

Using imperio ZCATransformer:
All transformers from imperio follow the transformers API from sci-kit-learn, which makes them fully compatible with sci-kit learn pipelines. First, if you didn’t install the library, then you can do it by typing the following command:
Now you can import the algorithm, fit it and transform some data. from imperio
zca = ZCATransformer()
X_transformed = zca.fit_transform(X,y)
As we said it can be easily used in a sci-kit learn pipeline.
from imperio import ZCATransformer
from sklearn.linear_model import LogisticRegression
pipe = Pipeline(
[
('zca', ZCATransformer()),
('model', LogisticRegression())
])
Besides the sci-kit learn API, Imperio transformers have an additional function that allows the transformer to be applied on a pandas data frame.
The ZCATransformer constructor has the following arguments:
- column_index (list, default = None): The list of indexes of the categorical columns to apply the transformer on. If set to None it will be applied to all columns.
The apply function has the following arguments.
- df (pd.DataFrame): The pandas DataFrame on which the transformer should be applied.
- target (str): The name of the target column.
- columns (list, default = None): The list with the names of columns on which the transformers should be applied.
Now let’s apply it to a data set. We will use it on the Pima diabetes data set. Note, we can apply it only to numeric data, so choose the columns if needed.
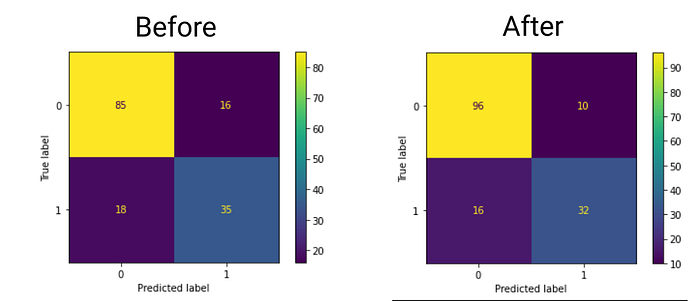
As we can observe from confusion matrices, initially we got 77% accuracy, and after applying ZCATransformer we obtained 83% accuracy.

Thank you for reading!
Follow Sigmoid on Facebook, Instagram, and LinkedIn:
https://www.facebook.com/sigmoidAI
https://www.instagram.com/sigmo.ai/
https://www.linkedin.com/company/sigmoid/